Building Powerful RAG Applications with Pinecone, OpenAI, and LangChain
> Explore how to build powerful RAG applications using Pinecone, OpenAI, and LangChain. Learn about the core concepts, implementation steps, and benefits of this approach for creating context-aware AI systems.
The landscape of AI is rapidly evolving, and RagAPP pinecone openai has emerged as a powerful combination for building sophisticated, context-aware applications. Retrieval Augmented Generation (RAG) addresses the limitations of Large Language Models (LLMs) by allowing them to access and utilize external knowledge sources. This article will explore how to create such a system, integrating the strengths of Pinecone for vector storage, OpenAI for language modeling, and LangChain for orchestrating the entire process. We will examine the core concepts, implementation steps, and benefits of this approach, drawing upon insights from multiple sources to provide a comprehensive understanding.
Understanding Retrieval Augmented Generation (RAG)
At its core, RAG enhances LLMs by integrating an information retrieval component into the generation process. LLMs, while powerful, are trained on static datasets, meaning they lack up-to-date information and domain-specific knowledge. This can lead to "hallucinations," where the model generates responses that sound convincing but are factually incorrect. RAG addresses this by fetching relevant data from an external database based on the user's query and providing it to the LLM as context. This allows the LLM to generate accurate, informed responses based on real-time data or specific knowledge bases.

Why RAG is Essential
RAG offers several key advantages:
- Up-to-date Information: LLMs are "frozen in time" and lack real-time data. RAG can provide current information, reducing the likelihood of hallucinations.
- Domain-Specific Knowledge: LLMs are trained for generalized tasks, meaning they don't know your company's private data. RAG provides the necessary context for domain-specific questions.
- Auditability: RAG allows GenAI applications to cite their sources, making the reasoning process more transparent and auditable.
- Cost-Effectiveness: RAG is often more cost-effective than fine-tuning an LLM or creating a new foundation model from scratch. It leverages existing models and adds external knowledge when needed.
The Role of Pinecone Vector Databases
Vector databases like Pinecone are a crucial component of RAG systems. They are designed to efficiently store and retrieve high-dimensional vector data. The process involves converting text or other data into vector embeddings, which are numerical representations capturing the semantic meaning of the data. Pinecone then allows for fast similarity searches based on these vectors.
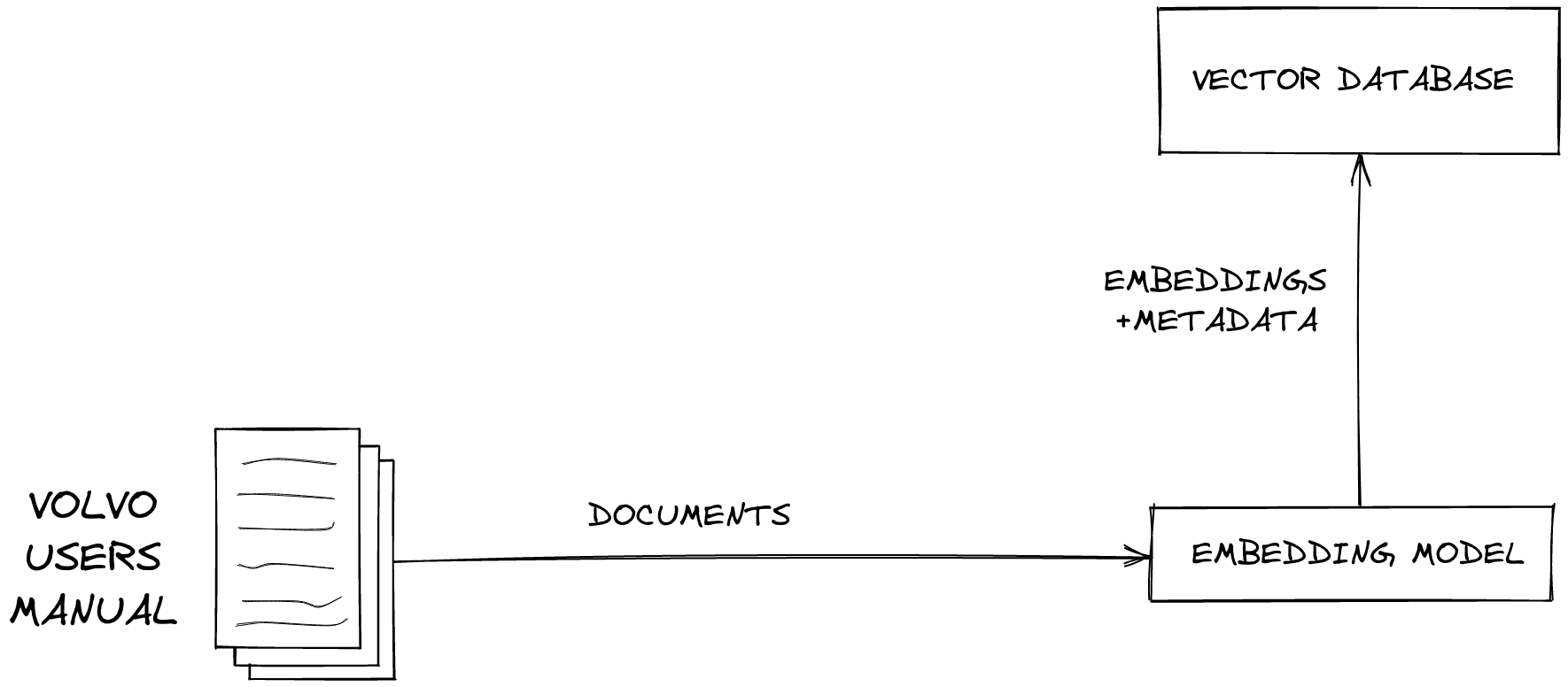
When a user submits a query, it's converted into a vector embedding, and Pinecone performs a similarity search to find the most relevant vectors in the database. The corresponding data is then retrieved and used as context for the LLM. This allows the system to retrieve semantically related information even if the user's query doesn't contain the exact keywords.
Why Pinecone?
Pinecone is a popular choice for vector databases due to its:
- Cloud-Based Service: Pinecone is a fully managed, cloud-based platform, eliminating the need for infrastructure management.
- Scalability: It is highly scalable, suitable for large-scale machine-learning tasks and real-time data ingestion with low-latency search.
- Purpose-Built: Pinecone specializes in handling high-dimensional data, making it ideal for RAG applications.
- Real-Time Updates: You can create vectors, ingest them into the database, and update the index in real-time, which is crucial for maintaining current information.
Integrating OpenAI for Language Modeling
OpenAI's models, such as GPT-4, provide the generative capabilities required for a robust RAG system. These models are trained on vast amounts of text data, enabling them to understand and generate human-like text. When combined with the context retrieved from Pinecone, these models can produce more accurate, relevant, and informative responses.
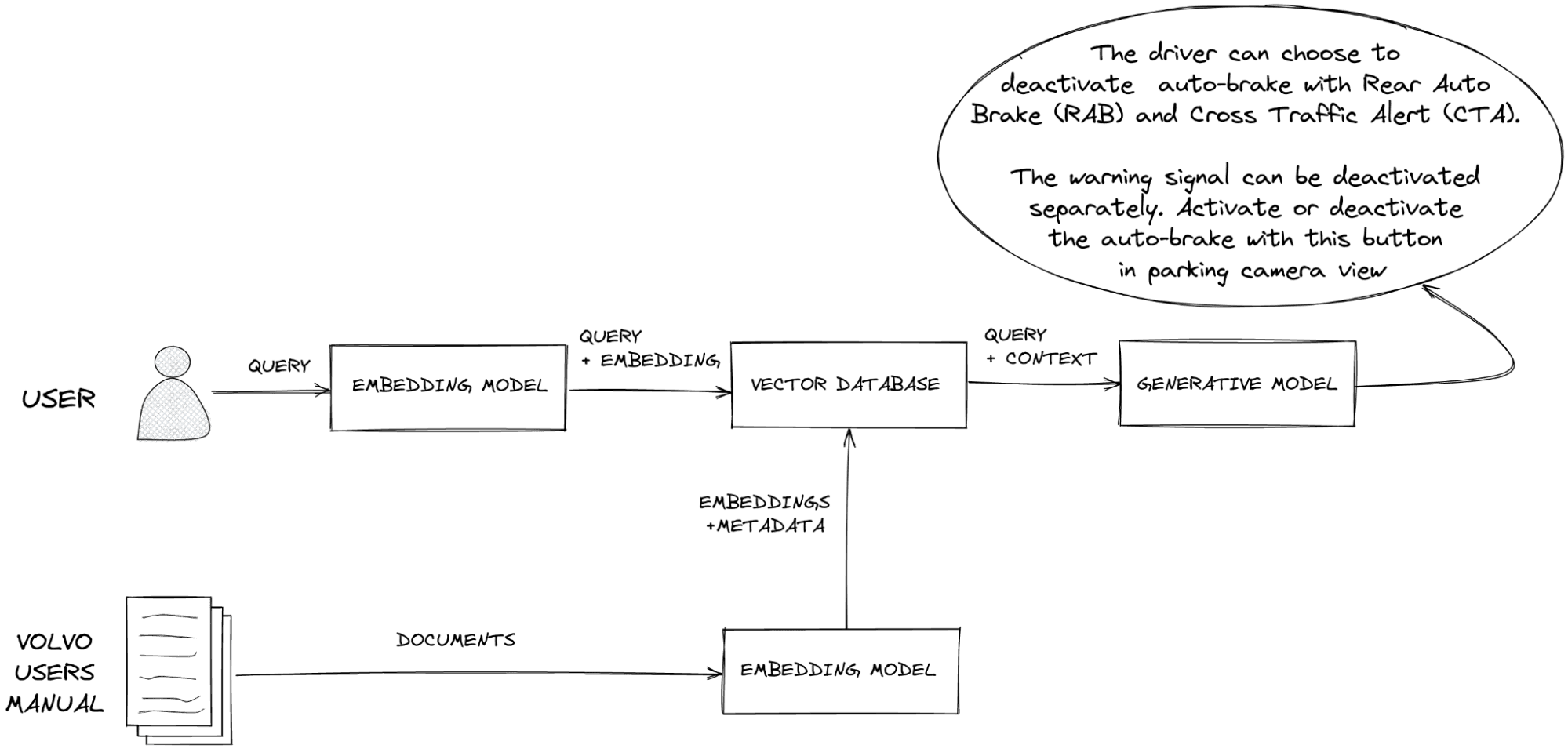
How OpenAI Models are Used in RAG
- Text Generation: OpenAI models generate the final response to the user query, utilizing both the query itself and the context retrieved from Pinecone.
- Embedding Generation: OpenAI's embedding models are used to convert text data into vector embeddings, which are then stored in Pinecone.
- Semantic Understanding: The models understand the semantic meaning of the text, allowing them to generate responses that are not just syntactically correct but also semantically relevant to the query and context.
Orchestrating with LangChain
LangChain acts as the glue that binds together the different components of a RAG system. It's a framework designed for developing applications powered by language models, allowing the models to be data-aware and agentic. LangChain provides tools and abstractions for interacting with LLMs, vector databases, and other data sources.
Key Features of LangChain
- Model Integration: LangChain seamlessly integrates with various LLMs, including OpenAI models.
- Data Connection: It provides connectors for various data sources, including vector databases like Pinecone.
- Chains: LangChain allows you to chain together different operations, creating complex workflows for RAG applications.
- Flexibility: LangChain is designed to be flexible, allowing developers to customize and extend its functionality to suit their specific needs.
Building a RAG Application: Step-by-Step
The process of building a RagAPP pinecone openai application typically involves the following steps:
- Data Preparation:
- Collect and clean the data. This may involve text files, PDFs, web pages, or other data sources.
- Split the text into smaller chunks for efficient processing and embedding.
- Embedding Generation:
- Use OpenAI's embedding models via LangChain to convert the text chunks into vector embeddings.
- Vector Database Setup:
- Create an index in Pinecone with the appropriate dimensions and distance metric.
- Upsert the vector embeddings along with the corresponding text chunks into the Pinecone index.
- Query Processing:
- When a user submits a query, embed it using the same OpenAI embedding model used for indexing.
- Use Pinecone to perform a similarity search and retrieve the most relevant vectors.
- Response Generation:
- Use LangChain to construct a prompt that includes the user query and the retrieved context.
- Pass the prompt to an OpenAI model to generate a final, informed response.
Practical Implementation Considerations
Several articles highlight the importance of specific implementation details:
- Chunking Strategies: How you split the text data into chunks can greatly impact the retrieval process. Options include fixed-size chunks, semantic chunks, or structure-based chunks.
- Prompt Engineering: Crafting effective prompts is crucial for getting the best results from the LLM. This involves providing clear instructions, context, and desired output formats.
- Top-k Retrieval: The number of documents retrieved from Pinecone during the search (top-k) can impact response quality. A higher top-k value yields more potential answers but increases the risk of irrelevant results.
- Error Handling: Implement robust error handling to gracefully manage issues such as corrupted files, API rate limits, or unexpected responses.
- API Integration: Building APIs for the RAG app using frameworks like FastAPI or Flask is recommended to enable seamless integration with other applications or user interfaces.
Example Use Cases
RagAPP pinecone openai can be applied to various use cases including:
- Chatbots: Create chatbots that can answer questions about specific products, services, or company policies.
- Content Creation: Generate high-quality, context-aware content for blog posts, articles, or social media.
- Personalized Recommendations: Provide personalized recommendations based on user history, preferences, or other relevant data.
- Legal and Medical Research: Access and analyze vast amounts of legal or medical information with unprecedented speed and accuracy.
Enhancing Performance
To further enhance the performance of a RagAPP pinecone openai system, consider the following techniques:
- Hybrid Search: Combine semantic search with keyword search for more accurate results.
- Reranking: Use a reranker model to refine the search results and select the most relevant documents.
- Multilingual Support: Use multilingual models to support queries in different languages.
- Continuous Learning: Regularly update the vector database with new information and fine-tune the model to improve its performance over time.
Conclusion
The combination of RagAPP pinecone openai offers a powerful solution for building advanced, context-aware AI applications. By leveraging the strengths of each component, developers can create systems that can generate creative, human-like text while also being able to retrieve and utilize specific pieces of information. As the field of AI continues to evolve, RAG systems will likely become increasingly important for a wide range of applications. The key is to experiment with different settings, models, and data sources to find the best configuration for a specific use case. With careful planning and implementation, these technologies can transform how we interact with and utilize AI.