How to Install and Run Llama 3.3 70B on a Local Computer: Step-by-Step Guide
> Learn how to install and run the Llama 3.3 70B large language model on your local computer with this detailed tutorial. Includes system requirements, installation steps, and performance tips.
Llama 3.3 70B is a powerful large language model (LLM) that combines efficiency with impressive performance. Designed to work on consumer-grade hardware, it’s perfect for users looking to harness AI locally without requiring a supercomputer. This guide provides detailed steps to install and run Llama 3.3 70B on your local machine, complete with images and troubleshooting tips.
Prerequisites
Hardware Requirements
- GPU: Minimum 24 GB VRAM (e.g., NVIDIA RTX 3090 or higher)
- CPU: Multi-core processor (e.g., Intel i9 or AMD Ryzen equivalent)
- RAM: At least 32 GB (48 GB recommended for smooth operation)
- Disk Space: Minimum 40 GB free
Software Requirements
- Operating System: Windows, macOS, or Linux
- Framework: Ollama for managing and running the model
- Command Line Proficiency: Basic familiarity with terminal commands
Step 1: Install Ollama
Ollama simplifies running language models locally with its intuitive command-line interface (CLI). Follow these steps to install it:
1.1 Download the Ollama Installer
-
Go to https://www.ollama.com.
-
Download the installer for your operating system.
-
Run the installer and follow the on-screen prompts to complete the installation.
Reference Image:
1.2 Verify the Installation
After installation:
-
Open your terminal or command prompt.
-
Type the following command and press Enter:
bash1ollama -
A successful installation will display a list of available commands.
Reference Image:
If you encounter errors, revisit the installation steps or check the Ollama troubleshooting documentation.
Step 2: Download and Run Llama 3.3 70B
With Ollama installed, the next step is to download and configure the Llama 3.3 70B model.
2.1 Access the Ollama Library
-
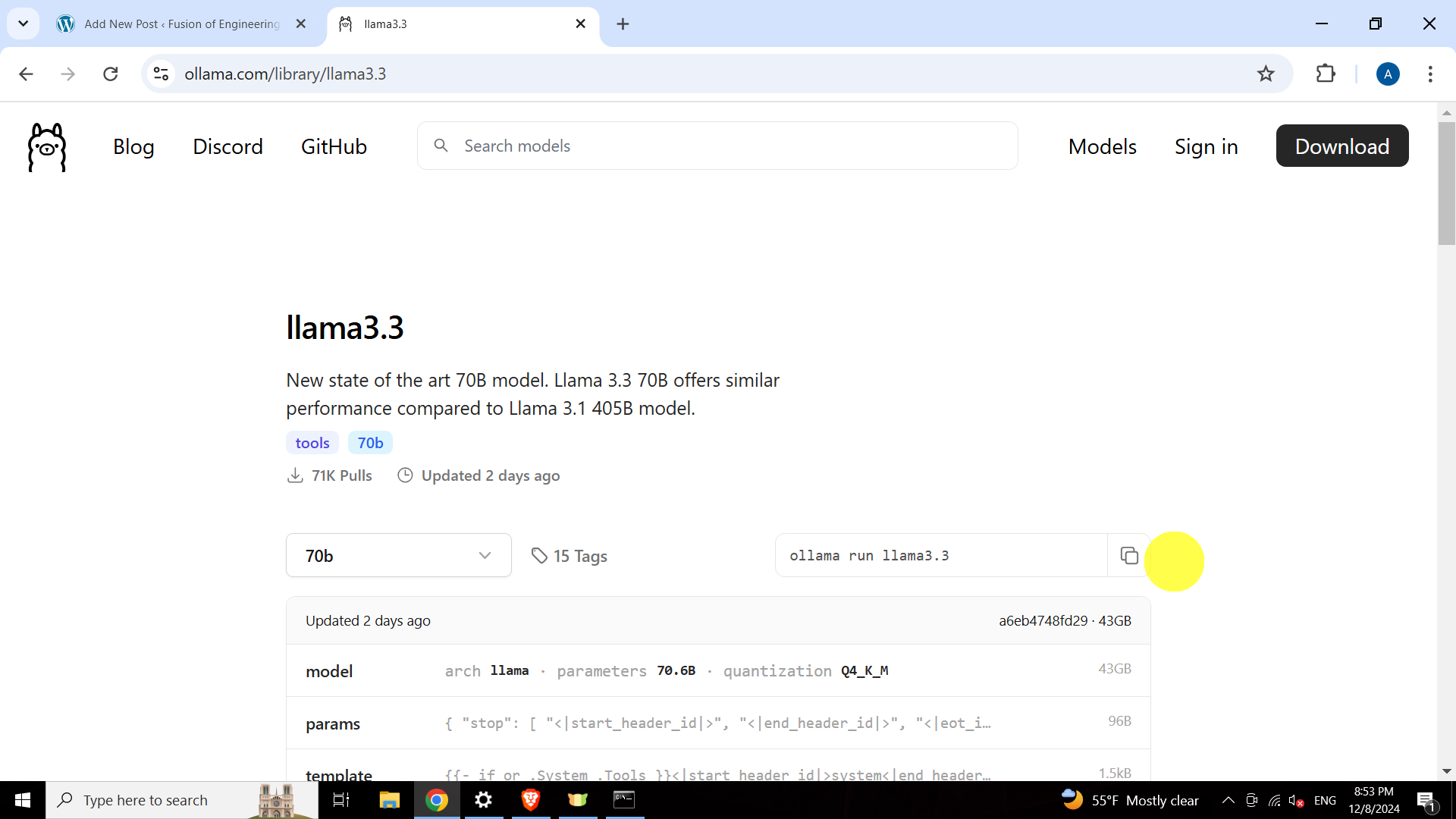
Visit the Llama 3.3 70B page in the Ollama library:
https://www.ollama.com/library/llama3.3. -
Copy the provided installation command (e.g.,
ollama run llama3.3).Reference Image:
2.2 Install and Launch Llama 3.3 70B
-
Open your terminal or command prompt.
-
Paste the command copied earlier and press Enter:
bash1ollama run llama3.3 -
Ollama will download and configure the model automatically. This process requires approximately 40 GB of disk space and may take time depending on your internet speed.
Reference Image:
Hardware Performance Tips
While Llama 3.3 70B is optimized for efficiency, here are some tips to maximize performance:
- GPU: Use a high-VRAM GPU like NVIDIA RTX 3090 or higher for faster inference.
- RAM: Ensure at least 48 GB of RAM to handle large model files.
- Disk Space: Store the model on an SSD for faster load times.
If performance is slow, consider reducing model precision (e.g., FP16) or optimizing parameters.
Common Issues and Solutions
-
Command Not Found:
- Ensure Ollama was added to your PATH during installation.
- Reinstall and check the environment variables.
-
Insufficient Disk Space:
- Clear unnecessary files or move the installation to a larger drive.
-
Slow Inference:
- Use a higher-end GPU or reduce the batch size in model parameters.
-
Model Download Fails:
- Check your internet connection and restart the process.
Conclusion
You’ve successfully installed and run Llama 3.3 70B on your local machine! This model’s blend of performance and efficiency makes it ideal for developers, researchers, and AI enthusiasts. As you explore its capabilities, consider tweaking performance settings and experimenting with use cases like text generation, summarization, and more.
Stay tuned for future guides on optimizing Llama 3.3 70B and applying it to real-world tasks!