Pinecone Results as String: Retrieving Text from Vector Embeddings
> Learn how to retrieve Pinecone results as strings instead of embeddings. This article explores the process of using Pinecone and other data sources to get human-readable text from vector search results.
In the realm of AI and vector databases, understanding how to retrieve meaningful information from embeddings is crucial. Often, the raw output from a vector database like Pinecone is an embedding – a numerical representation of the data. However, for many applications, we need the actual text or string representation. This article will explore how to obtain Pinecone results as string not embedding, drawing from various resources that detail the process of using embeddings and Pinecone. We will examine the underlying concepts, the practical steps involved, and how to effectively retrieve textual data rather than just the embedding vectors.
Understanding Embeddings and Vector Databases
Before diving into the specifics of retrieving string results, it’s important to grasp what embeddings are and how vector databases function. Embeddings are numerical representations of text or other data, where similar items have vectors that are close to each other in the vector space. Vector databases, like Pinecone, are designed to store and efficiently search these embeddings.
The core idea is that instead of searching for exact matches, you're searching for semantic similarity. The embeddings capture the meaning of the text, allowing you to find related documents, even if they don't share any words. This is particularly useful in applications like semantic search and creating context for large language models.
The Challenge: From Vectors to Strings
The primary challenge lies in the fact that a vector database like Pinecone stores and retrieves vectors, not strings. When you query Pinecone, the response will typically contain the vector embeddings of the most similar items, along with their IDs and any metadata you've stored. To get the actual text, you need to use those IDs to look up the corresponding string data from another source. This could be your main data store, a relational database, or even a document database.
Strategies for Retrieving String Results
Several strategies can be employed to get Pinecone results as string not embedding. The key is to use the IDs returned by Pinecone to retrieve the actual text from your data storage system.
Linking Pinecone IDs to Your Data
The most common method is to use the IDs of the vectors returned by Pinecone to look up the associated text in your own database. When you upsert data into Pinecone, you should store these IDs in a way that is easily retrievable.
For example, if you have a document stored in a relational database, you might use the primary key of that document as the ID when upserting its embedding to Pinecone. Then, when you query Pinecone and get a matching vector ID, you can directly query your relational database using that ID to fetch the associated text. This mapping is crucial for converting from vector search results to human-readable content.
Using Metadata to Store Text (With Caution)
While you can technically store text directly in Pinecone metadata, this approach has limitations. Pinecone indexes all metadata by default, and storing large amounts of text can quickly fill up your index. Therefore, it's generally better to store minimal metadata, such as categories or keywords, and keep the full text in a separate database. The metadata can be used for filtering queries, but it’s not efficient for storing large text payloads.
Example Workflow: Convex and Pinecone
One example of a workflow, as illustrated by the provided content, uses Convex and Pinecone. In this system, the text is initially stored in a Convex database and a corresponding embedding is stored in Pinecone. When a search is performed, Pinecone returns the vector IDs. These IDs are then used to look up the actual text data stored in Convex.
This workflow highlights the importance of linking the IDs between the vector database and your primary data store, ensuring that you can retrieve the original text associated with the embeddings.
Practical Implementation Steps
Here's a practical breakdown of the steps to retrieve Pinecone results as string not embedding, based on the provided documents:
- Prepare Your Data: Break down your source data into bite-sized chunks. This helps with embedding quality and prevents issues with context length limits. Libraries like LangChain can assist with this process.
- Create Embeddings: Generate embeddings for each chunk of text using a service like OpenAI or Cohere. These embeddings are numerical representations of your text.
- Store Data in Your Database: Store the original text chunks in a database like Convex or a relational database.
- Upsert to Pinecone: Upsert the embeddings into Pinecone, making sure to use the same IDs that you used for storing the text in your database. Include relevant metadata, such as document IDs, but avoid storing large text fields here.
- Query Pinecone: When a user performs a search, convert the search query to an embedding and use it to query Pinecone.
- Retrieve IDs: Pinecone will return a list of vector IDs that are similar to the query embedding.
- Fetch Text: Use the returned IDs to retrieve the corresponding text from your database.
- Return Results: Present the retrieved text strings as results to the user.
Code Examples
While the provided articles don't give specific code examples of fetching strings, here's a conceptual illustration based on the processes described.
python1# Assume you have Pinecone results with IDs 2pinecone_results = [ 3 {'id': 'doc123', 'score': 0.95, 'vector': [0.1, 0.2, ...]}, 4 {'id': 'doc456', 'score': 0.88, 'vector': [0.3, 0.4, ...]} 5] 6 7 8# Assume you have a function to fetch text by ID 9def fetch_text_from_db(doc_id): 10 # This would query your database and return the text 11 if doc_id == 'doc123': 12 return "This is the text for document 123" 13 elif doc_id == 'doc456': 14 return "This is the text for document 456" 15 else: 16 return "Document not found" 17 18# Retrieve the actual text 19text_results = [] 20for result in pinecone_results: 21 doc_id = result['id'] 22 text = fetch_text_from_db(doc_id) 23 text_results.append({'id': doc_id, 'text': text, 'score': result['score']}) 24 25# Print the results 26for result in text_results: 27 print(f"ID: {result['id']}, Score: {result['score']}, Text: {result['text']}")
This example shows how you would use the IDs returned from Pinecone to retrieve the text from another data source.
Streaming and Real-Time Processing
The provided articles also discuss real-time processing using Databricks and Pinecone. In this scenario, the process is similar but needs to be more streamlined.
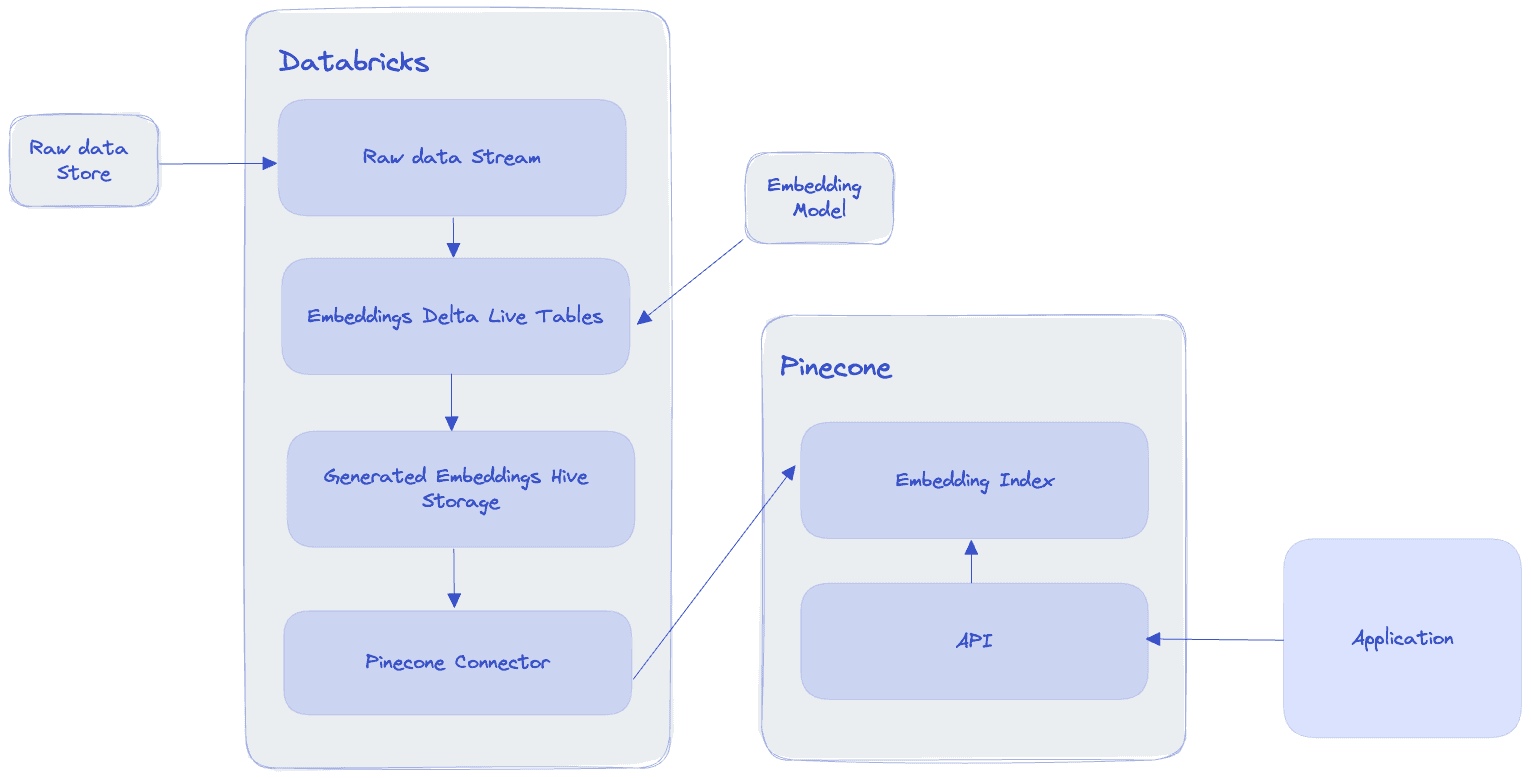
Data is ingested, cleaned, and embeddings are generated in real-time using a pipeline. The embeddings are then written to Pinecone, and the original text is stored in a separate table. When a search is performed, the same process of using IDs to fetch the text is applied. This real-time processing approach allows for continuous updates and efficient querying of data. The keys to success are a robust architecture and an efficient method of linking your Pinecone IDs to your data.
Conclusion
Getting Pinecone results as string not embedding requires a two-step process: first, querying the vector database to find relevant vectors, and then using the returned IDs to retrieve the actual text from your primary data store. By carefully managing your data, linking IDs effectively, and understanding the limitations of metadata, you can build applications that leverage the power of semantic search and provide human-readable results. Whether you are working with static data or real-time streams, the key is to maintain a clear separation between embeddings and original text, ensuring that your application can efficiently retrieve and display the desired string results.